
前言:当AI学会了“创造”,世界将如何改变?
近两年,从能写代码、会写诗的ChatGPT,到“一句话换一幅画”的Midjourney,生成式AI(Generative AI)以一种近乎“魔法”的姿态闯入了我们的生活。一时间,似乎万物皆可生成,人人都在讨论AIGC。但这股热潮也带来了许多困惑:这种“新”AI,和我们早已习惯的垃圾邮件过滤器、人脸识别等“旧”AI,到底有什么本质区别?我们又该如何驾驭这股强大的“创造力”,将它应用到像推荐系统这样的经典场景中?甚至,它能反过来把传统AI的“判断”工作也一并包揽吗?
本文将带你从底层逻辑出发,厘清生成式AI与传统判别式AI的根本差异,并深入探讨两大前沿应用方向:如何用生成式AI重塑推荐系统,以及它如何“降维打击”传统的分类判别任务。无论你是技术决策者、产品经理还是AI爱好者,相信读完这篇文章,你对生成日志AI的认知将焕然一新。
一、 本质之别:当“艺术家”遇见“裁判员”
要理解生成式AI与传统AI的区别,我们首先要明确,我们通常所说的“传统AI”,在很多场景下指的是判别式AI(Discriminative AI)。这两者的关系,就像一位无拘无束的艺术家和一位铁面无私的裁判员。
判别式AI:精准的“裁判员”
想象一个经验丰富的裁判员,他的任务是根据选手的表现(输入数据X),给出一个明确的判决(输出标签Y)。比如,在垃圾邮件分类这个经典任务中,判别模型的职责就是学习一个决策边界,当一封新邮件进来时,它能迅速判断出“这封邮件是垃圾邮件的概率有多大?”。
从数学上讲,判别模型的核心是学习条件概率 P(Y|X)——即在给定输入X的条件下,输出Y的概率。它的目标是“分类正确”,追求的是高准确率、低错误率。它的输出通常是结构化的、确定性的,比如“是/否”、“猫/狗”、“0.98的概率是垃圾邮件”。它能告诉你“像什么”,但无法告诉你“是什么”的全部。
生成式AI:富有创造力的“艺术家”
现在,让我们把目光转向生成式AI这位“艺术家”。它的任务不是判断,而是“创造”。你给它一个主题(Prompt),比如“夕阳下的海边城堡,赛博朋克风格”,它就能挥洒画笔,创作出一幅前所未有的画作。这幅画既符合你的描述,又充满了它自己独特的“想象力”和随机性。
生成式AI的底层逻辑完全不同。它不满足于学习决策边界,而是致力于理解和学习整个数据的联合概率分布 P(X,Y),甚至是数据的边缘概率 P(X)。这意味着,它不仅要知道“垃圾邮件长什么样”,还要有能力“凭空捏造出一封看起来非常逼真的垃圾邮件”。它的训练目标不再是“分类正确”,而是“生成逼真”,让生成的内容与真实数据难以区分。
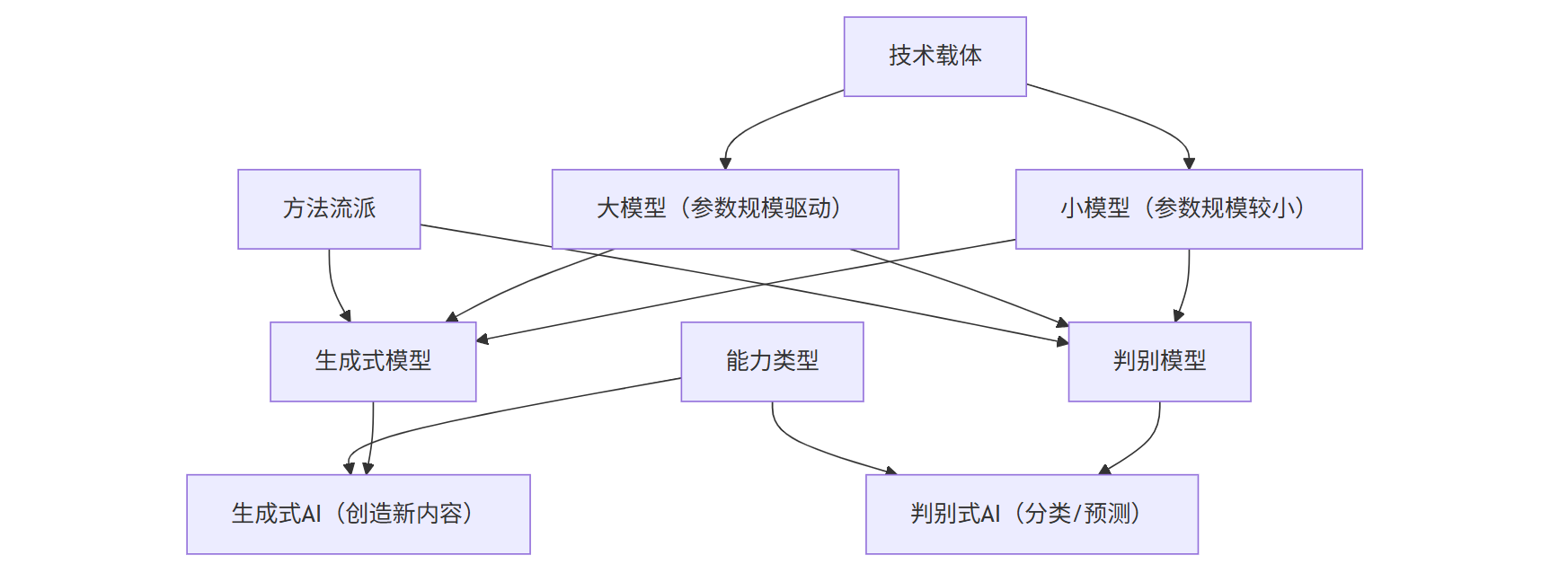
本质区别小结:
| 特性 | 判别式AI (裁判员) | 生成式AI (艺术家) |
|---|---|---|
| 核心任务 | 分类、回归、决策 | 创造、生成新内容 |
| 学习目标 | `P(Y | X)` (条件概率) |
| 训练目标 | 最小化分类错误率 | 最大化生成逼真度 |
| 输出特点 | 确定性、结构化、低维 | 随机性、创造性、高维 |
| 数据依赖 | 精准标注数据 | 海量(通常是无标注)数据 |
| 典型代表 | 逻辑回归、支持向量机、XGBoost | GPT系列、Stable Diffusion、GAN |
二、 应用革新:如何用“生成”思维重塑推荐系统?
理解了本质区别,我们来看第一个激动人心的应用问题:如何将生成式AI融入推荐系统?这不仅仅是技术的替换,更是一场思维范式的革命——从“猜测用户喜好”到“理解并续写用户故事”。
传统推荐系统:一个优秀的“猜心游戏”
传统的推荐系统,本质上更接近于一个判别式任务。其核心问题可以归结为:“给定用户U和物品I,预测用户U点击/购买物品I的概率是多少?” 这就是一个典型的 P(Y|X) 问题,其中X是(用户画像,物品特征),Y是(点击/不点击)。无论是协同过滤还是基于内容的推荐,模型都在学习一个“打分函数”,通过预测用户可能的高分项来进行推荐。
这种方法的优点是成熟、高效,但也有其局限性:
- 数据稀疏性问题:对于新用户或冷门物品,难以进行准确预测。
- 探索与利用的困境:倾向于推荐用户已表现出兴趣的相似物品,难以发现用户的潜在新兴趣,容易形成“信息茧房”。
- 无法理解动态意图:难以捕捉用户兴趣的实时、序列化演变。用户上午想买咖啡,下午可能就在看露营装备,传统模型很难跟上这种节奏。
生成式推荐系统:化身用户的“灵魂写手”
生成式AI提供了一个全新的视角。它不再将推荐视为一个孤立的“预测”任务,而是将其看作一个序列生成任务,类似于GPT生成文本。
其核心原理如下:
-
用户行为序列化:我们将用户的历史行为(点击、浏览、购买、收藏等)看作一个按时间排序的“句子”,每个行为(物品)就是一个“单词”。例如,一个用户的行为序列可能是
[物品A, 物品B, 物品C, ...]。 -
学习用户行为“语法”:利用强大的序列模型(如Transformer架构,这也是GPT的核心),让模型学习这个“句子”的内在逻辑和“语法”。模型需要理解,在看了物品A和B之后,用户为什么会接着看物品C。它学习的是物品之间的复杂、高阶的关联性。
-
生成未来的“篇章”:推荐任务就变成了:“给定用户当前的行为序列(上文),请生成最有可能的下一个行为(续写下文)”。模型不再是预测一个点击率,而是直接**生成(Generate)**一个或多个它认为用户接下来会感兴趣的物品ID。

这种范式的优势是颠覆性的:
- 理解动态意图:Transformer的自注意力机制天生擅长捕捉序列中的长距离依赖关系,能够更好地理解用户兴趣的流动和演变。
- 缓解数据稀疏:通过学习海量用户序列的通用模式,模型可以为新用户或行为较少的用户生成更合理的推荐,因为它懂得了“一类人”的行为范式。
- 创造性与多样性:生成模型可以推荐一些意想不到但又高度相关的物品,打破“信息茧房”。就像一个优秀的作家,它能写出既符合人物性格又充满惊喜的情节。
简而言之,传统推荐系统在问:“根据你的过去,我猜你喜欢这个吗?” 而生成式推荐系统在说:“我读懂了你的故事,接下来最精彩的篇章应该是这个。”
三、 跨界打击:生成式AI能做判别式任务吗?原理何在?
既然生成式AI如此强大,它能否“降维打击”,把传统判别模型的活儿也干了?答案是肯定的,而且方式非常巧妙,主要依赖两大原理:基于提示的推理(Prompt-based Inference)和作为特征提取器的能力。
原理一:万物皆可Prompt,将判断转化为生成
大型生成式模型(尤其是语言模型)在海量的无标注数据上进行预训练,已经内化了关于世界的大量知识。我们可以通过精心设计的提示(Prompt),将一个判别任务“伪装”成一个生成任务。
以情感分类为例,这是一个典型的判别任务。
- 传统做法:准备数万条标注了“积极/消极”的评论,训练一个分类器。
- 生成式做法:我们直接向GPT这样的模型提问,而无需任何额外的训练。
Prompt示例:
请判断以下这条评论的情感是“积极”、“消极”还是“中性”。
评论:“这款耳机的音质超出了我的预期,但佩戴舒适度有待提高。”
情感:
模型会根据其对语言的深刻理解,生成出最可能的答案,比如“中性”或“积极”。这个生成出来的词,就是我们想要的分类标签。
这个过程的巧妙之处在于,我们利用了模型在预训练阶段学到的P(X)——对语言本身的理解。模型知道“超出预期”是褒义,而“有待提高”是贬义,它通过计算在给定上下文中,哪个标签词(“积极”、“消极”、“中性”)出现的概率最高,从而完成了一次“零样本(Zero-shot)”或“少样本(Few-shot)”的分类。这对于缺乏大量标注数据的场景来说,是革命性的。
原理二:强大的“特征提取器”,为判别模型赋能
生成式AI的另一个强大之处在于其学习到的表示(Representation)或嵌入(Embedding)。模型内部的神经网络层,特别是像CLIP或BERT这样的模型,能够将输入数据(如文本、图像)转换成一个高维的、信息量极大的数字向量(即Embedding)。
这个向量可以被看作是原始数据的一个极其精炼和深刻的“特征摘要”。它捕捉了数据最本质的语义信息。
应用流程如下:
- 特征提取:将需要分类的数据(例如,一条用户评论)输入到一个大型生成式模型中。
- 获取嵌入:我们不关心模型最终生成了什么,而是从模型的中间层提取出这条评论对应的嵌入向量。
- 下游任务:将这个高质量的嵌入向量,作为输入特征,喂给一个非常简单、轻量的传统判别模型(如逻辑回归或一个小型神经网络)。
在这个流程中,生成式大模型扮演了一个“超级特征工程师”的角色。它免去了我们手动设计特征的繁琐工作,并提供了远比传统方法(如词袋模型)更强大、更具语义的特征。这使得即便是一个简单的判别模型,也能在这些高质量特征的加持下,达到极高的分类性能。
四、 拨开迷雾:如何在实践中做出明智选择?
生成式AI虽好,但并非万能灵药。盲目追捧“大模型”,或者试图用生成式AI替代所有判别任务,都是常见的行业误区。在实际应用中,我们需要像一位经验丰富的指挥家,为不同的乐器(模型)分配最合适的乐章(任务)。
-
认清任务本质:创造力 vs. 确定性
- 生成式AI的舒适区:内容创作(文案、代码、图片)、对话交互、模拟预测等需要开放性、创造力和多样性的任务。
- 判别式AI的护城河:金融风控、医疗诊断、内容审核等需要高精度、高确定性、低错误率和良好可解释性的场景。正如Forrester的研究指出,在这些领域,生成式AI的“创造性”可能带来不可控的风险,而判别模型因其决策过程相对透明而更受青睐。
-
拥抱混合架构:强强联合,取长补短 最明智的做法往往不是“二选一”,而是“强强联合”。例如,在风控场景中,可以先用生成式AI从海量用户中生成一个“高风险候选人列表”,再用精准的判别模型对这个小范围列表进行逐一审查和最终决策。这既利用了生成式模型的发现能力,又保证了判别模型的决策严谨性。
-
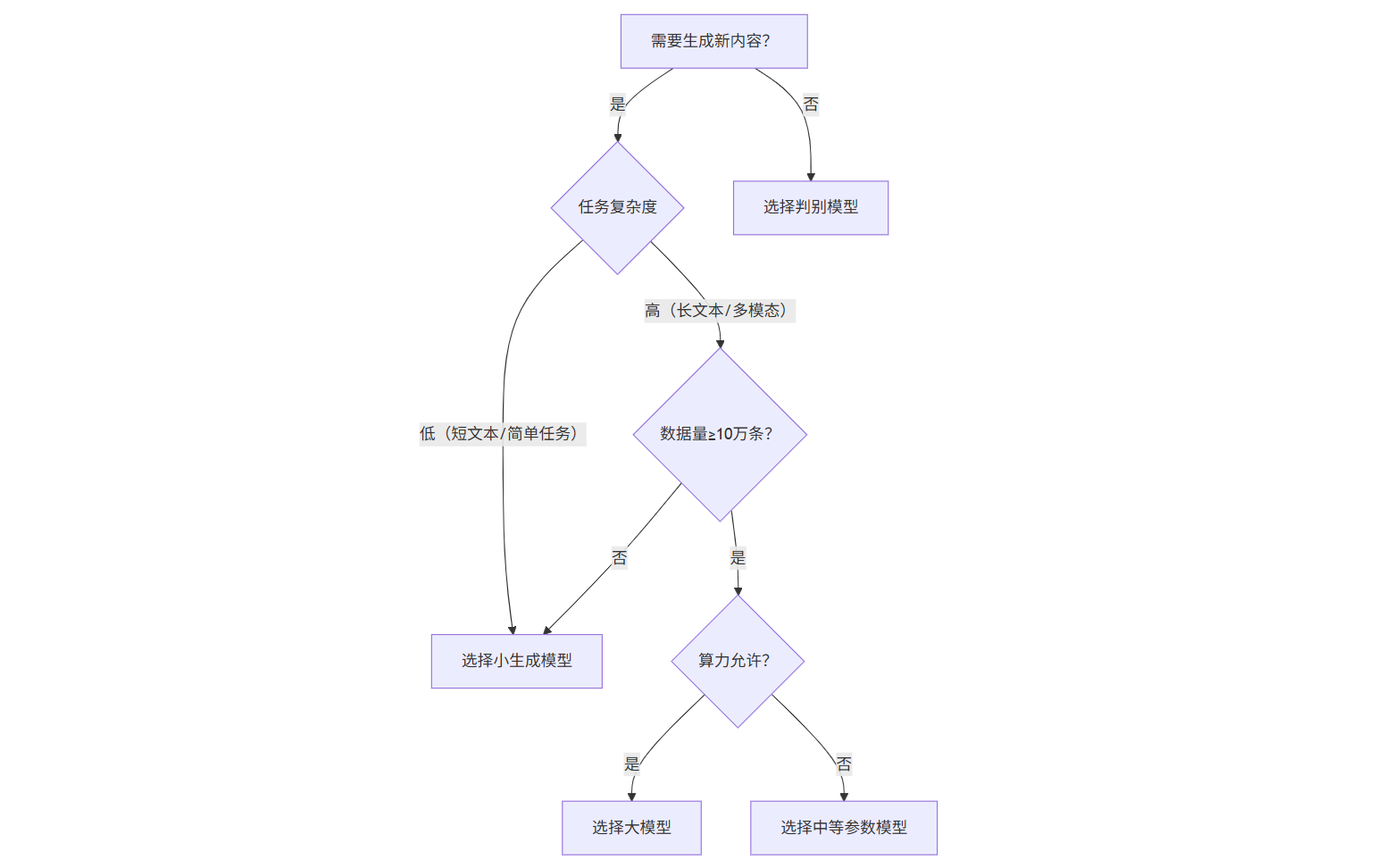
模型选型:不选最“大”,只选最“对” “参数越大越好”是一个危险的误区。根据任务复杂度、数据量和算力成本,做出理性选择至关重要。
- 简单任务(如短文本分类):轻量级判别模型或小参数生成模型足矣。
- 中等任务(如长文本摘要):中等规模的模型可能是性价比之选。
- 复杂任务(如跨模态生成、法律文书撰写):才需要动用千亿级的大模型。
总结:AI盛宴中,选对你的“厨具”与“菜系”
回到我们最初的比喻,如果说AI技术是一场盛大的烹饪,那么:
- 判别式AI就像一本本精准的菜谱,你给它食材(数据),它就能严格按照步骤,做出一道标准化的菜肴(决策)。
- 大模型则是一位才华横溢的米其林主厨,他拥有深厚的功底(巨大的参数和知识),不仅能按菜谱做菜,更能即兴发挥,创造新菜式(生成能力)。
- 而生成式AI,则是整个现代烹饪体系。它既需要主厨的创造力(大模型的生成能力),也离不开对烹饪基本原理的遵循(其内部也蕴含着判别逻辑)。
理解了生成式AI与传统判别式AI的本质区别,我们便能洞悉其在推荐系统等领域的应用原理,并巧妙地让“艺术家”客串“裁判员”的角色。这不仅仅是技术知识的扩充,更是我们在这个AI新纪元中,从一个被动的追随者,转变为一个能够驾驭技术、创造价值的主动参与者的关键一步。下次当有人再将它们混为一谈时,你便可以自信地告诉他:选对厨具,才能烹饪出真正的AI盛宴。
机构
合作







